Boxxology
Customize your Sub Box Business
technologies











Overview
Boxxology is a SaaS application to manage and customize your Subscription Business. Using Boxxology, one can import Orders, Subscriptions, Customers and their complete information from Subscription Marketplaces like Cratejoy. One can also import their inventory into Boxxology and can then Curate Shipments for a Customer based on his/her preferences and past Orders. Once the Shipment has been curated, one can ship the orders via ShipStation to the designated Customer.
Without Boxxology, curating Subscriptions specific to a Customer based on his/her preferences is a pretty painful process and is a very time consuming process.
TECHNOLOGY
Boxxoloyg's Technology platform is based on Django and is deployed on AWS using AWS ECS.
When Boxxology founders brought the idea to us, the requirements were mostly in written form but no mockups existed to depict how each functionality should look like or behave. From day one, we built the CI/CD pipeline using GitLab so that as soon as we commit the code, it is deployed to a testing website, and the founder's expectations match with what we build.
There were several challenges to build the Boxxology platform. Given it was supposed to be a SaaS application, we had to choose what kind of multi-tenancy system we should choose to build the platform. There are three approaches we could have chosen viz.
- One Database Per Tenant
- One Schema Per Tenant but Shared Database
- Same Schema for All Tenants
Each one has its own benefits and drawbacks. With One Database Per Tenant, management of multiple databases and deployments is not an easy feat. The advantages being that the database for one Tenant is completely isolated and provides the best security model. With second approach, which is natively supported by Postgres, each Tenant has its own Table but different Schemas. And the third optin is to have a shared database and shared Schema. We chose the last option as we wanted to design things for scale and Sharding on tenant_id would scale better than other scenarios.
The other thing we wanted to achieve was having automatic deployments with no manual setup of EC2 Instances, RDB Instances, S3 buckets, IAM, Load Balancer, VPC and a bunch of other AWS services that we were planning to use for the project. We chose to use Terraform for creating Infrastructure which could be represented completely using Code, also known as IaaC. This allowed us to incrementally make changes to our infrastructure without breaking out existing Infrastructure as we could review the changes to the Infrastructure before deployments.
The other challenge we had, was to fetch all the data for a Store from Cratejoy when the Store owner signups for the first time. Stores could have lots and lots of data, and thus the goal was to pull the data for a Store as quickly as possible and in case of network or other errors, retry fetching the data from where it failed. Thus splitting and scheduling the fetching of whole Store data was a big challenge. Once the data was pulled, we also had to ensure that it was inserted in ElasticSearch and properly indexed. We also had to ensure that the data for one Store does not get mixed up with data of other Stores while inserting in ElasticSearch of while storing in our own Database. Finally the user had to be continuously notified when the various tasks for fetching the data completed and how much percentage was finished as the Store owner waited for the data being fetched from Cratejoy.
For all the background tasks, we chose Celery and monitoring using Flower. While Celery allows one to hit the ground pretty easily but configuring various parts that interact with Celery, be it AMQP backend, which in our case was RabbitMQ, results backend, ensuring different queues have different priotities, retrying of failed jobs, signaling of completed jobs to the user and splitting of jobs, is not so easy.
For Search we used ElasticSearch using django-elasticsearch-dsl, which provides for easy integration to Django Models without redeclaring the model fields for Storing the documents in ElasticSearch.
Web Images
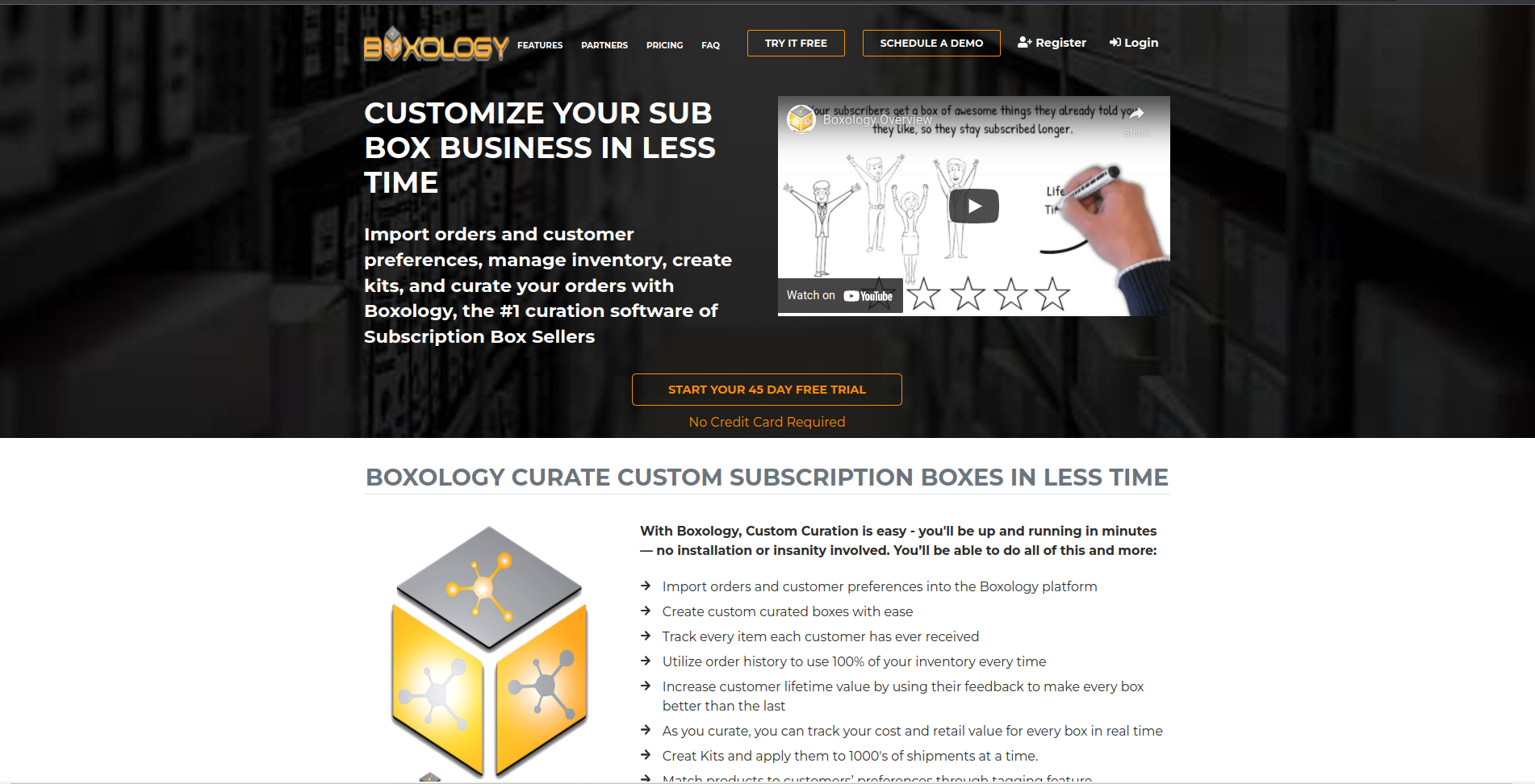
Landing page
Store Login
Store registration
Boxxology DashBoard
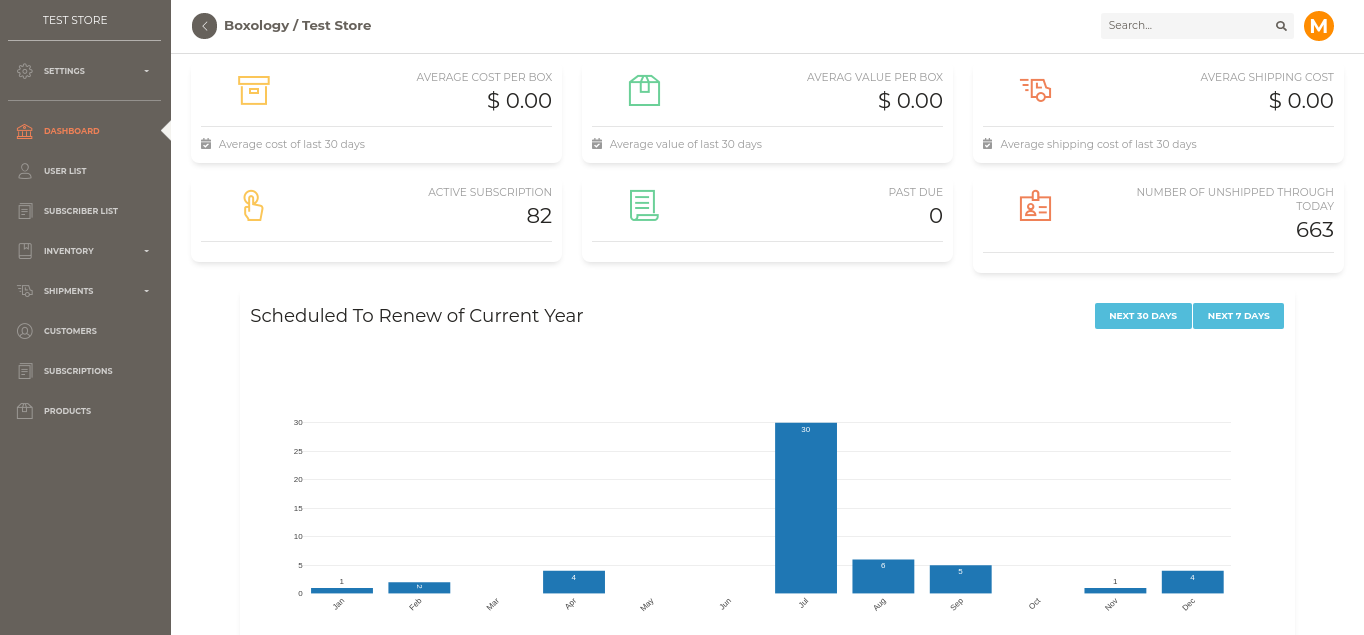
Store Subscriptions
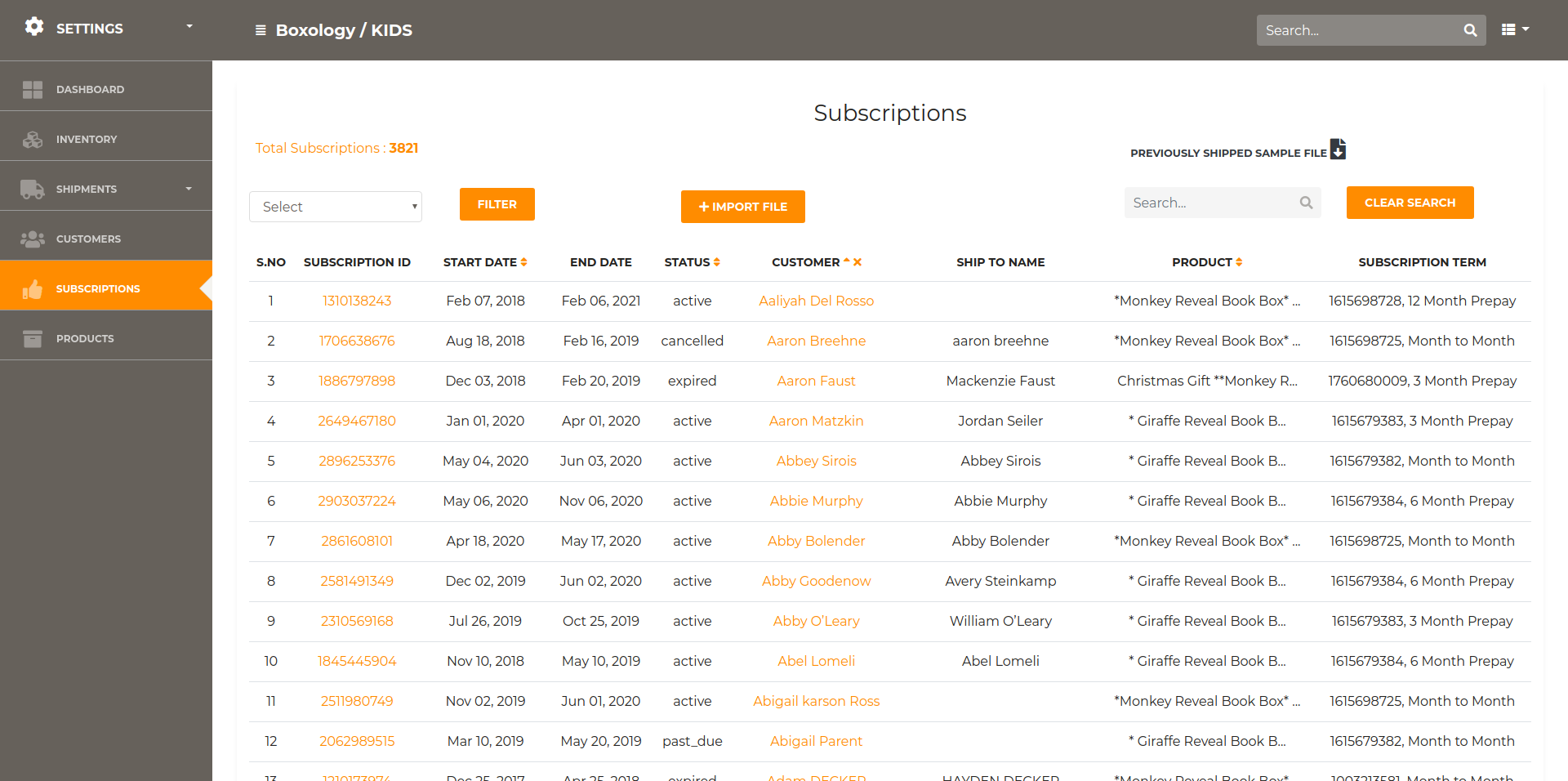
Account Setup for Cratejoy and Shipstation
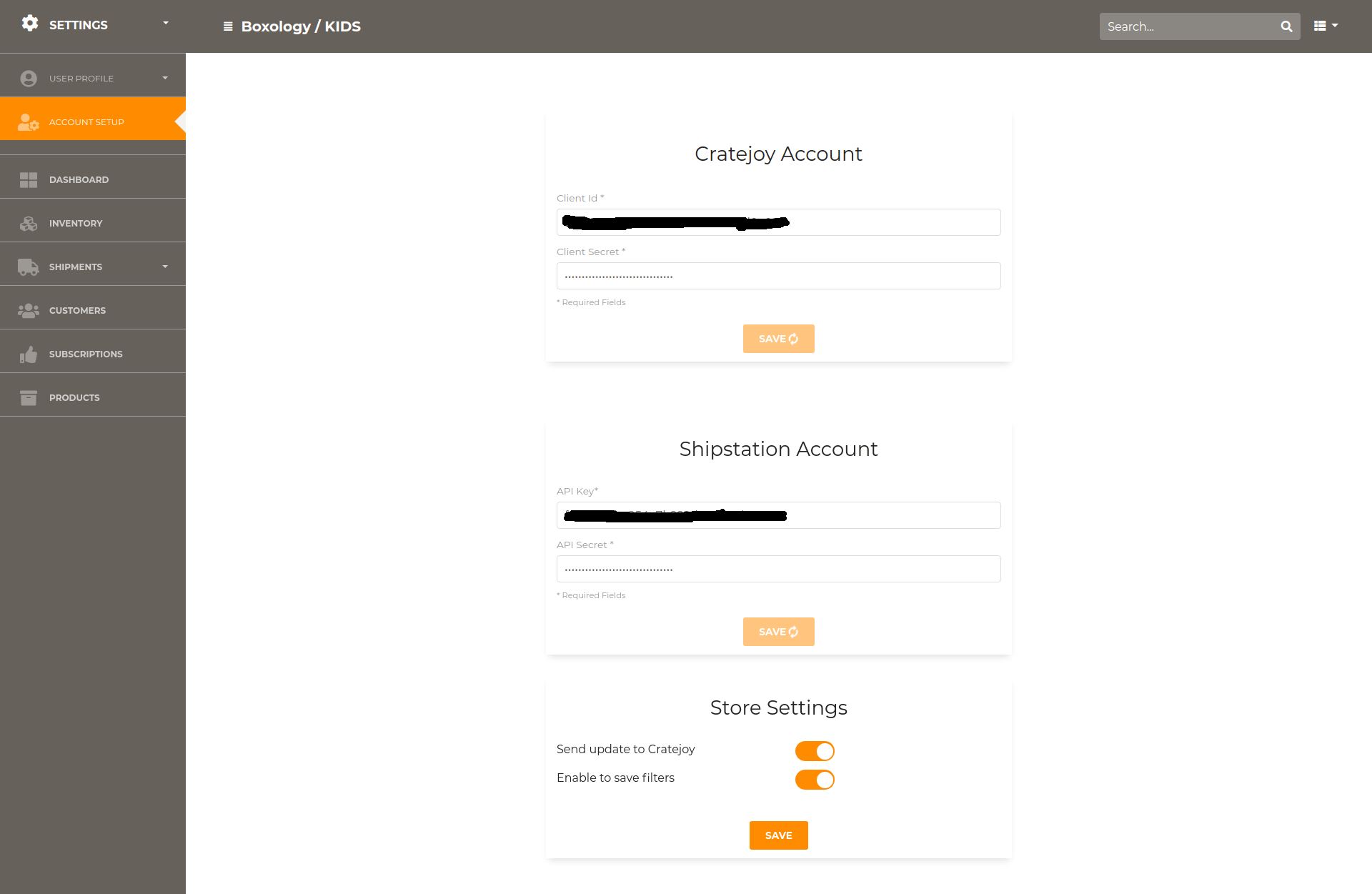
Store Unshipped Fulfillments
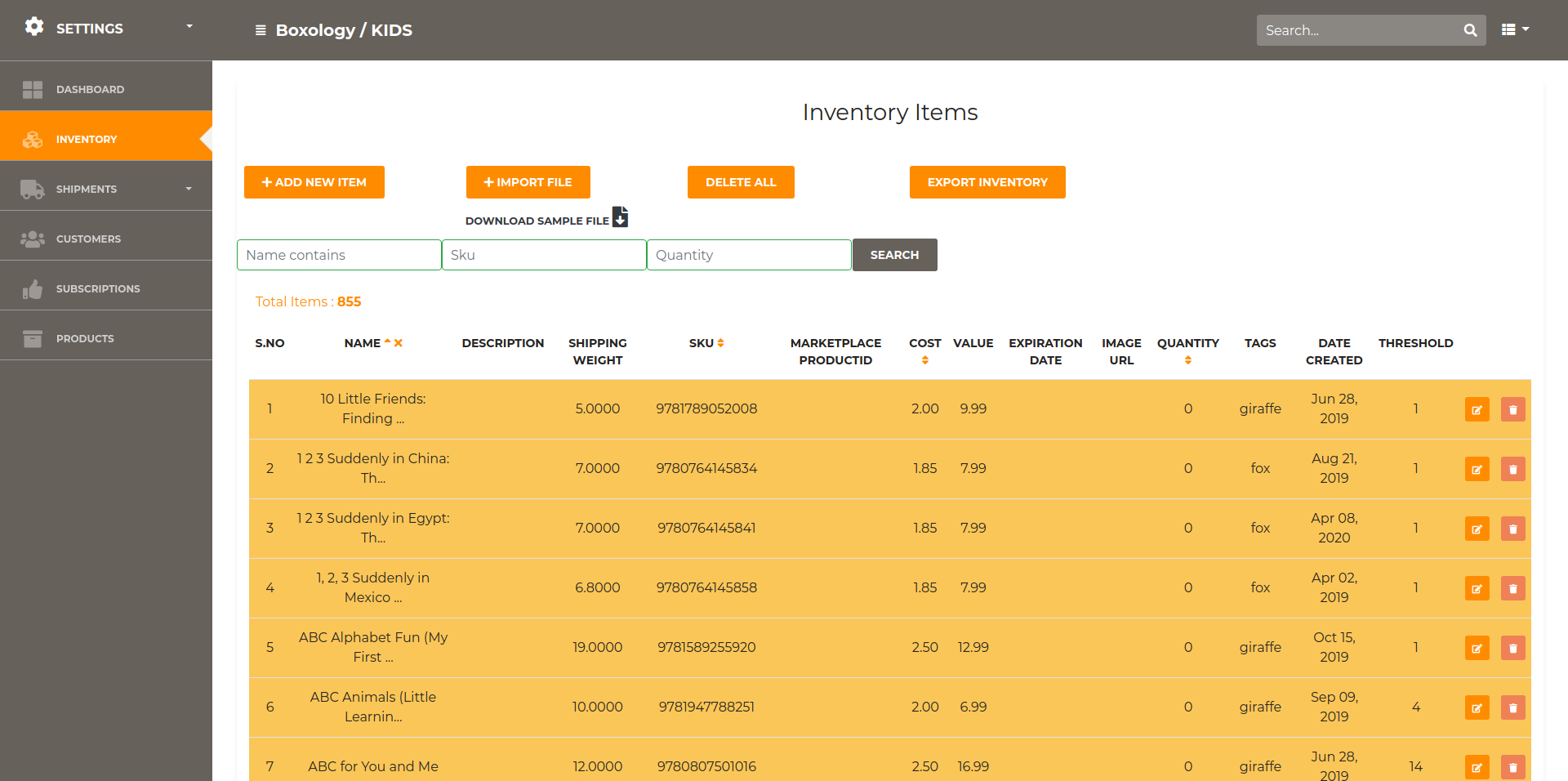
Store Inventory
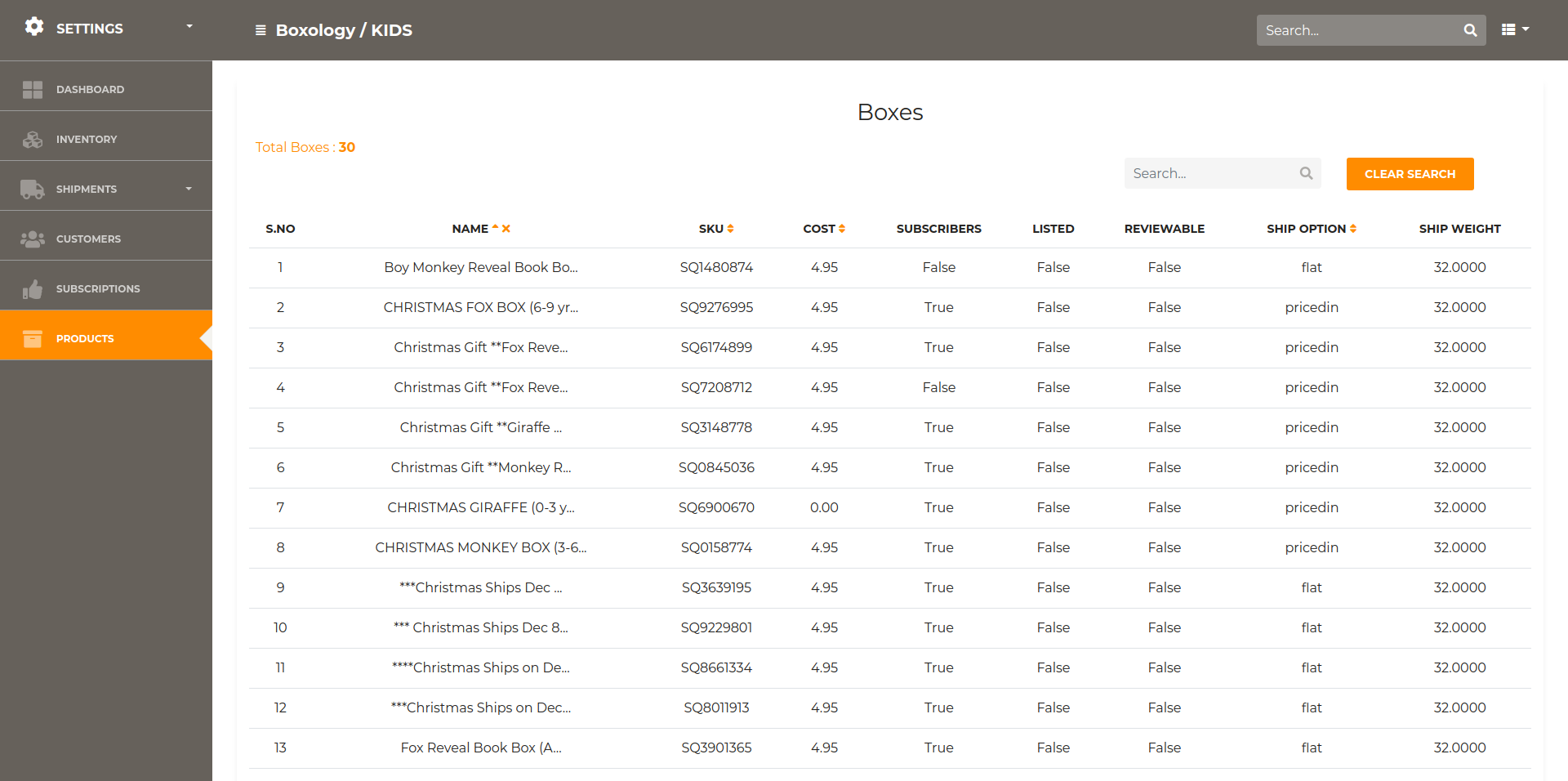
Store Products / Boxes
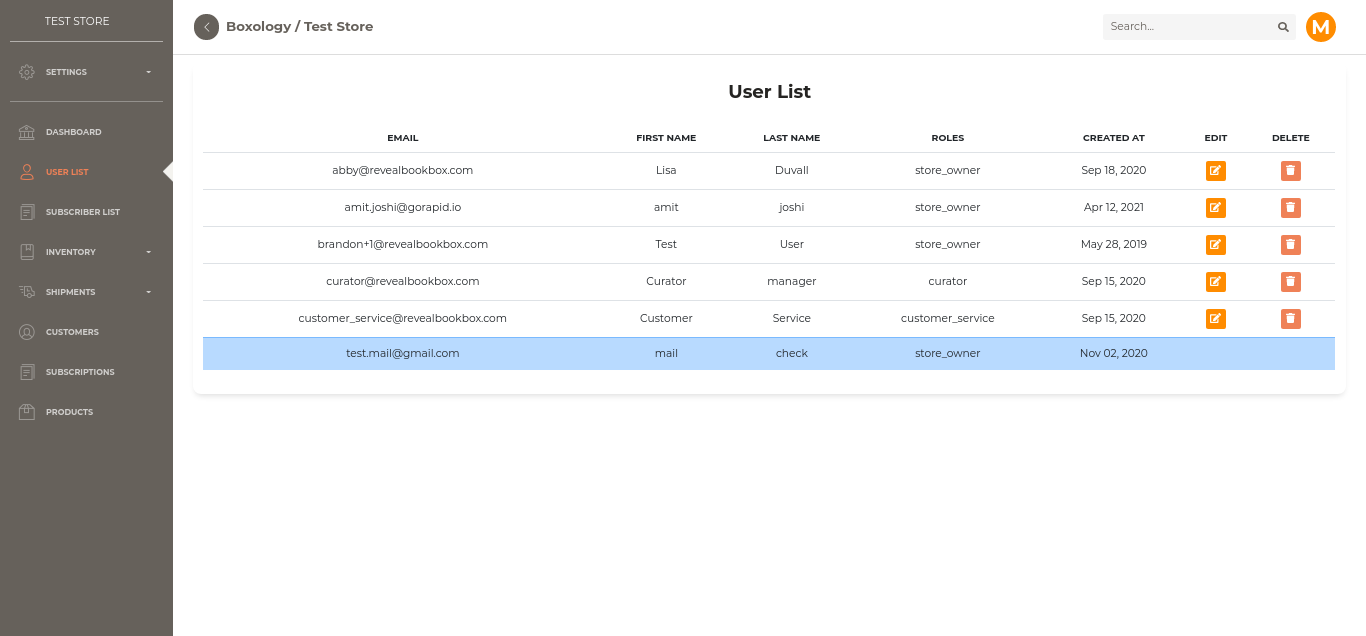
Store User List
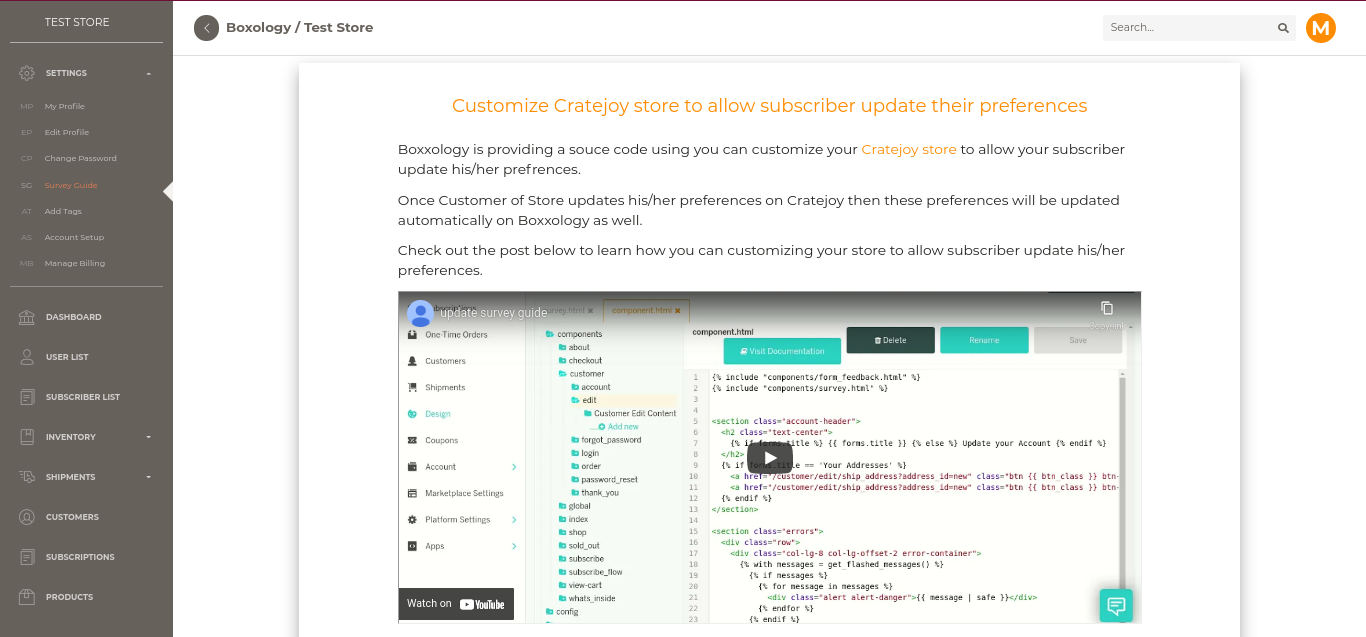
Cratejoy Update Survey Guide
Subscriber List
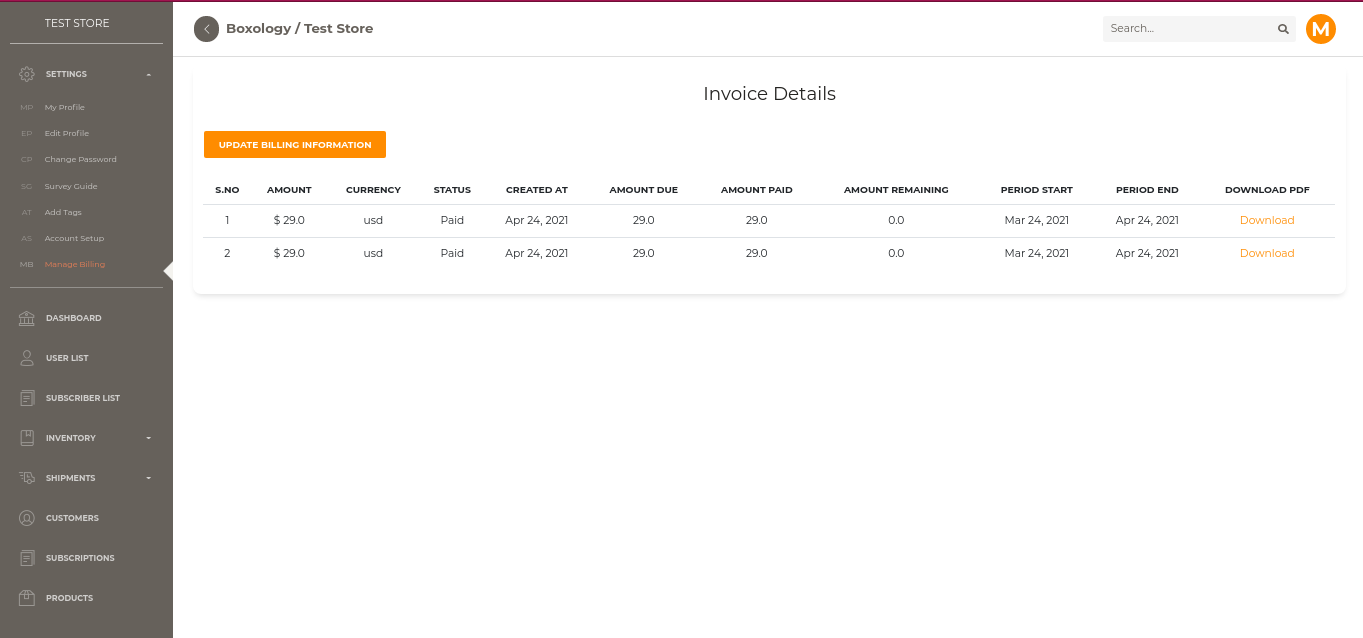
Invoice Details